
シミュレーターを駆使してCPUらしきものを作りました。これまで前例のない2ビットCPUです…。最低でも4ビットのCPUにしたかったのですが、シミュレーターの制約により2ビットになりました。
2ビットCPUでは、プログラムは最大4ステップ、計算やレジスタの桁数も2ビット(0~3)です。計算は足し算のみです。これはシミュレーターの性能限界の範囲を考えてこのような仕様になりました。
図1. CircuitJS1でCPUぽいものを作る
ここから拡大できます。
回路についての説明です。まず、図2 をご覧ください。黄色のライン部分がクロックで、すべてのD-フリップフロップに繋がっています。赤がリセットで、こちらもすべてのD-フリップフロップに繋がっています。リセットをhighにすると、すべてのD-フリップフロップがリセットされ、プログラムが最初から開始(リセット)される仕組みです。青が制御線です。ここはどの回路を利用するかを制御する部分で重要です(「命令デコーダー」の部分で詳しく説明します)。
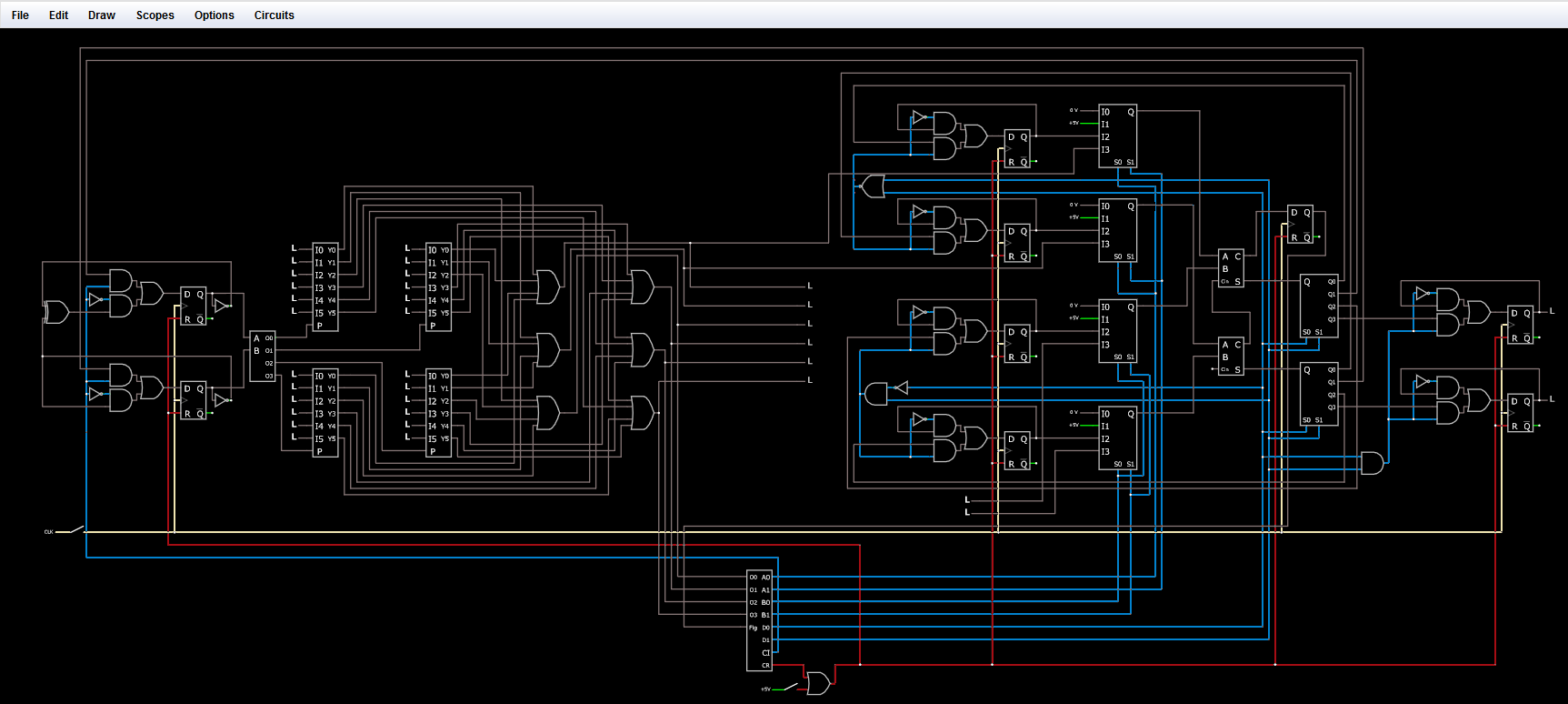
図2. 配線の説明
次に各部分の解説です。
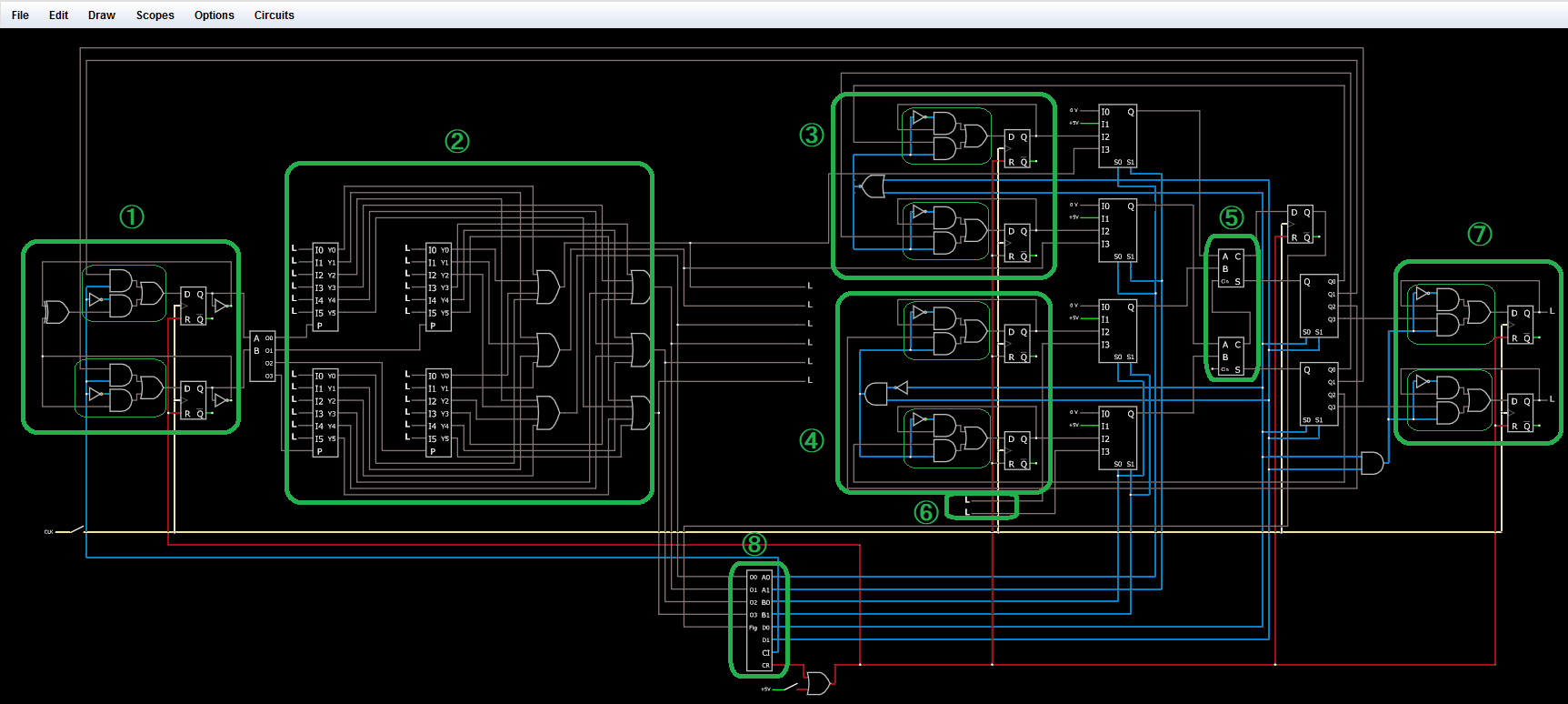
図3. 配線の各部分の説明
①は2ビットのカウンターです。クロックごとに00→01→10→11→00と繰り返されます。ただし、細い緑の四角で囲った部分は2ビットのマルチプレクサとなっていて、制御線がHighの場合は戻ってきている2線のほうの値がカウンタにセットされるようになっています。つまりプログラムの移動を担っています。
②はプログラムを格納するいわゆるROMです。4ステップしか入力できません。1つのプログラムは6ビット(I0~I5)でセットします。左上から時計回りに繰り返し実行されます。PがHighのときY0~Y5に出力され、②の右側に出た6本の線に選択されたプログラムがそのまま出力される仕組みです。プログラムはI0,I1は即値(プログラムに直接書き込まれた値)で、I2~I5を使ってプログラムの動作を指定します(オペコード)。つまりプログラムは4ビット=16種類の動作を指定できます。
③と④はいわゆる汎用レジスタで一時的にデータを保持するものです。2ビットのレジスタが2つ分用意されています。上をAレジスタ、下をBレジスタと呼ぶことにします。
⑤は2ビット同士の加算器です。2ビット同士の和は0~6になりますが、2ビットまでしか扱えないため、計算結果が4~6の場合は桁あふれとなり、右上のレジスタにHighがセットされます。
⑥と⑦は外部入力と外部出力です。外部入力値はプログラムの即値やAレジスタ(および00や11)と加算できます。
⑧は命令デコーダーです。プログラムのI2~I5の4ビット(00~03)と桁あふれの状態から、8本の出力を使ってどの回路を有効にするかを決めます。8本の出力のうち、CRはリセット線に繋がっているので、他の制御線がどうであろうとここをHighにするとプログラムがリセットされることになります。
出力は、A0,A1はAレジスタの隣にあるマルチプレクサに繋がっていて、「00」、「Aレジスタ」、「11」、「プログラムの即値」、のうちどれを利用するか指定します。B0,B1はBレジスタの隣にあるマルチプレクサに繋がっていて、「00」、「Bレジスタ」、「11」、「外部入力」、のうちどれを利用するか指定します。D0,D1は加算の結果をどこに出力するかを決めます。D0,D1が00の場合Aレジスタに、01の場合Bレジスタに、10の場合カウンタに、11の場合外部出力レジスタに出力されます。(※カウンタの値を変えるには、CIもHighにする必要があります)。桁あふれがあった場合、右上のレジスタ(D-フリップフロップ)に1(high)が設定されます。このラインは⑧の命令デコーダーの入力に繋がっており、レジスタが入ることにより桁あふれが起きた次のクロックで動作を制御できるようになっています。つまりこれは条件分岐のためのフラグレジスタということになります。
命令デコーダーICのデフォルトの設定は以下のようになっています(?はdon’t care(=0,1の両方)。より上が優先。出力を変えれば別の機能を割り当てられます。シミュレーターのICをダブルクリックして[Edit Model…]から編集できます。):
O0,O1,O2,O3,Flg=A0,A1,B0,B1,D0,D1,CI,CR 0000?=00001000 何もしない (nop) 00010=00001000 桁あふれでない場合、何もしない 00011=11001010 桁あふれの場合、即値にジャンプ 00100=00001000 桁あふれでない場合、何もしない 00101=01001010 桁あふれの場合、Aレジスタの値にジャンプ 0011?=11001010 即値にジャンプ 0100?=00110000 外部入力をAレジスタに保存 0101?=11000000 即値をAレジスタに保存 0110?=00110100 外部入力をBレジスタに保存 0111?=11000100 即値をBレジスタに保存 1000?=01000100 Aレジスタの値をBレジスタに保存 1001?=00010000 Bレジスタの値をAレジスタに保存 1010?=01010000 Aレジスタ+Bレジスタの値をAレジスタに保存 1011?=01010100 Aレジスタ+Bレジスタの値をBレジスタに保存 1100?=00111100 外部入力の値を外部出力レジスタに保存 1101?=01001100 Aレジスタの値を外部出力レジスタに保存 1110?=00011100 Bレジスタの値を外部出力レジスタに保存 1111?=01011101 リセット ?????=00001000 何もしない
シミュレータのROMはデフォルトで以下のプログラムが設定されています:
00: 00110000: 外部入力(01)の値をAレジスタに保存(→01) 01: 11000100: 即値(10)をBレジスタに保存(→10) 10: 01010000: Aレジスタ(01)+Bレジスタ(10)の値をAレジスタに保存(→11) 11: 11000000: 即値(00)をAレジスタに保存(→00) ※00から繰り返す
結局、近年のRISC CPUでオペコードに割り当てられる機能は大きく分けて、「レジスタへの入出力」「メモリ(主記憶装置)への入出力」「即値やレジスタ(やメモリ)の値を使った演算」「条件分岐とジャンプ」の4つだと思っています(他にも権限命令等ありますが、大雑把に4つと考えます)。今回のCPUは外部への入出力の命令がある一方、メモリの搭載を考えていないので、メモリへの入出力の命令がありません。近年のCPUでは、外部入力や出力に関連する命令が直接的に存在しないことが一般的です。代わりに、外部デバイスとの通信はメモリマップドI/O(Memory-Mapped I/O)という方式を通じて行われたりします。これは、特定のメモリアドレスにデバイスのアクセスを割り当て、CPUから見るとメモリアクセスで外部デバイスとデータの送受信を行う方法です。また、今回のCPUはプログラムはROM上に設定しますが、通常プログラムはメモリに保存されたものを読み出して使用します。メモリには他にもレジスタだけでは処理しきれないデータを保存したり読み出したりする役割もあります。
メモリアクセスはCPU内蔵のレジスタに比べると非常に遅いですが、近年のCPUでもレジスタは30個くらいしかなく(しかもそれぞれ役割が決まっていて汎用的に使えるレジスタはごく少数)、そのため、レジスタは効率的に使用し、それ以外の計算やデータのやりとりはメモリを使って行うことになります。ちなみに、プログラムと計算用のメモリが物理的に別に用意されている方式を「ハーバード・アーキテクチャ」と呼びます。PICマイコンなどはこれに当たり、プログラム用メモリのバスと、計算用メモリのバスが分離できるため、回路構造が比較的シンプルになります。対して、プログラムとデータが同じメモリを共有する方式を「フォン・ノイマン・アーキテクチャ」と言います。通常のPCは「フォン・ノイマン型アーキテクチャ」ということになります。ノイマン型はメモリ装置が1つで済むため効率的に見えますが、メモリを扱う命令では「命令の取得」と「データアクセス」の要求を同時にメモリ装置に対して行うことになり、1クロックで完結させようとすると問題が生じます。
解決方法としては、1つの命令を2クロック使って実行することが考えられます。つまり1クロック目ではプログラムを取り出すためにメモリを使用し、2クロック目でデータを取り出すためにメモリを使用する(そして1クロック目に戻る)といった方法です。
もちろん、実際にはメモリは近年のCPUクロックに対して極めて低速であり、そこを考えれば(どうせ待ちが発生するので)些細な問題に見えます。実際に近年のCPUにはメモリアクセスを高速化するために、メモリの値を先読みして保存しておくキャッシュ機能があります。キャッシュは頻繁にアクセスするデータを予測し予めメモリから取り出しておき、CPUのデータアクセス効率を高めています。命令アクセス用のキャッシュと、データアクセス用のキャッシュを別々に用意すれば、同時アクセスも可能でしょう。しかしいずれにしても、1クロックですべての処理を行おうとすると、CPUの機能が複雑になるにつれて回路や装置の資源の奪い合いが起きるのは間違いなさそうです。
実際、通常のCPUは1つの命令を1クロックで完結する構造になっていることは少なく、一般的には命令サイクルという、1つの命令を複数のクロックに分けて(ステージに分けて)実行する構造になっています。これは資源の奪い合いを避けるためでもありますが、もっと重要なのは、1クロックごとのクリティカルパスを短くするためでもあります。以前説明したようにクリティカルパスが長いと、回路に信号を伝達するために十分な時間を与える必要があり、CPUのクロック数を抑える必要があります。逆に、回路を機能ごとに分割する(途中に保存レジスタを入れる構造にする)と、1命令を実行するのに必要なクロック数が増えても、回路は機能ごとのシンプルな構造になりますし、何よりクリティカルパスが短くなることにより、クロック数を高速化することができます。
クロック数を増やしても、1命令に使うクロック数が増えてしまっては意味があるのだろうかと思われるかもしれません。
実際にはパイプライン処理という方法が使われます(図4)。パイプライン処理は1命令を複数のステージに分けて実行する際に、1ステージごとにずらして複数の命令を同時に実行する方式です。例えば、命令サイクルが、「1.命令フェッチ→2.命令デコード→3.命令実行→4.メモリアクセス→5.ライトバック」のように5ステージだった場合、最初の命令が「1.命令フェッチ」を行い、次のクロックで2.を実行している間に、2番目の命令が1.を実行するという具合です。これが理想通り動けば、最初の数クロックを除いては、実質1命令1クロックで動作していることになるわけです。
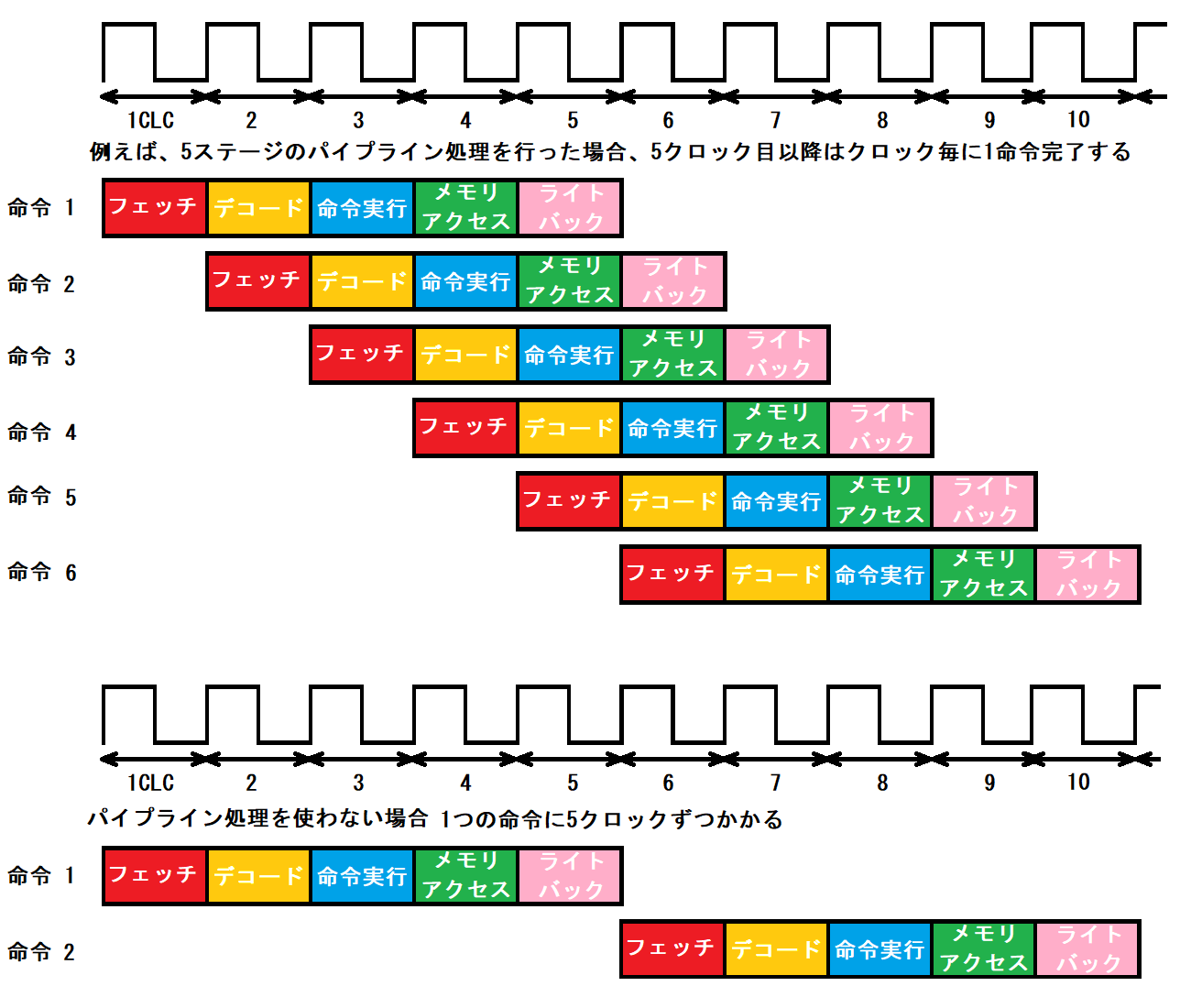
図4. パイプライン処理
もちろん、1命令が終わらないうちに次の命令を実行し始めるため、例えば1つ前の命令の結果を次の命令が利用する場合や、条件分岐がある場合、また周辺資源を同時に利用しようとする場合などで問題が生じます。これをハザードといい、追加回路(や場合によってはソフト)等でうまく工夫して解決する必要があります。(実際にはこの辺は「パタヘネ本(第5版)」という書籍で私は学んでいるので、読んでいただければより詳しく理解できると思います。)そのため、パイプライン処理を使っても理想通りに1クロック1命令を実行することは実質的には難しいですが、現実的には30%~70%程度の効率で実行できるとのことです。
他にも今回のCPUになく、一般的なCPUには存在する回路として「割り込み」(インタラプト)という機能があります。割り込みとは、CPUが特定の条件やイベントに応じて、実行中のタスクを一時停止し、即座に別の処理を行うメカニズムのことです。たとえば、キーボードのキーが押されたときや、プログラムが特定の条件に達した(システムコールや例外処理等)ときに割り込みは発生します。
割り込みが発生すると、まずCPUは現在実行中のタスクを一時停止し、状態を保存(退避)します。次に、割り込みに対応する特定の処理を行う割り込みサービスルーチン(ISR:通常ユーザ側で動作をプログラムする)が実行され、これが完了すると、CPUは退避しておいた状態を復元し、元タスクの実行を再開します。割り込みが複数同時に発生した場合に備えて、通常は優先順位が設定されており、優先度の高い割り込みから処理されます。
ちなみに、割り込みの他にポーリングという方法もあります。これはCPUが定期的に特定の状態やイベントをチェックしに行く方式です。しかしこの方式だとCPUが何もすることがない場合でも、デバイスの状態を定期的にチェックする必要があり、この間CPUは通常のタスクを処理できないことになります。また、チェックのタイミングによっては、応答が遅れる原因にもなります。このため、通常CPUはポーリングではなく、割り込み方式を使うことが多いのです。

他にも現代のCPUでは、スーパースカラ技術や、インテルのハイパースレッディング技術、マルチコア化、最近ではSoC化などが進んでおりより複雑化してきています。
また、著名なCPUについては、CPUのマシン語命令セットや動作の仕様として「命令セットアーキテクチャ(Instruction Set Architecture、ISA)」が予め定義されており、これに沿って回路が設計されることになります。ISAの代表的なものとしては、x86、Arm、MIPS、PowerPC、RISC-Vなどがあります。特に、RISC-Vはオープンソースのアーキテクチャとして近年注目を集めています。
また、AI化の進展に伴い、SoC(System on Chip)ではCPUコアだけでなく、GPUコアやNPU(Neural Processing Unit)コアなど、さまざまな種類のコアを複数搭載することが増えつつあります。