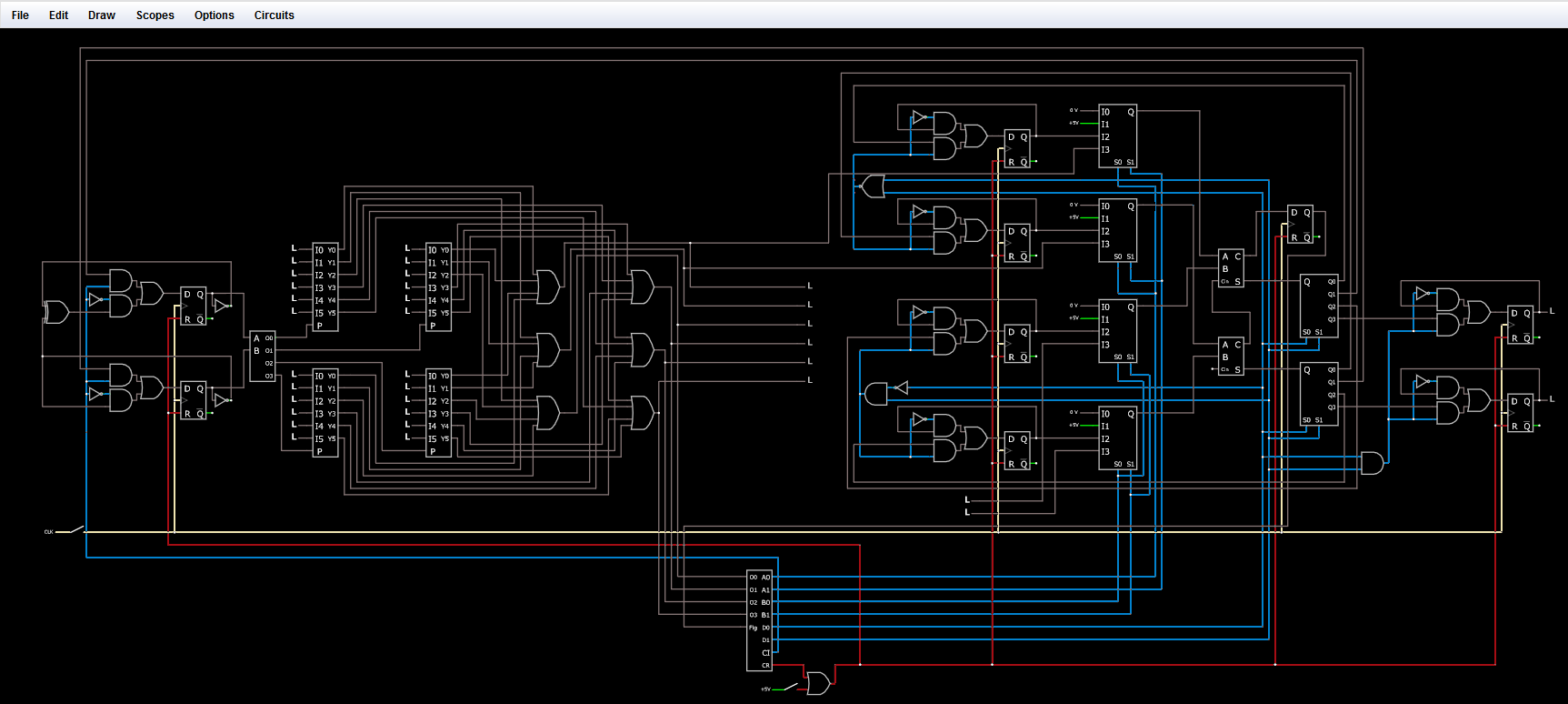
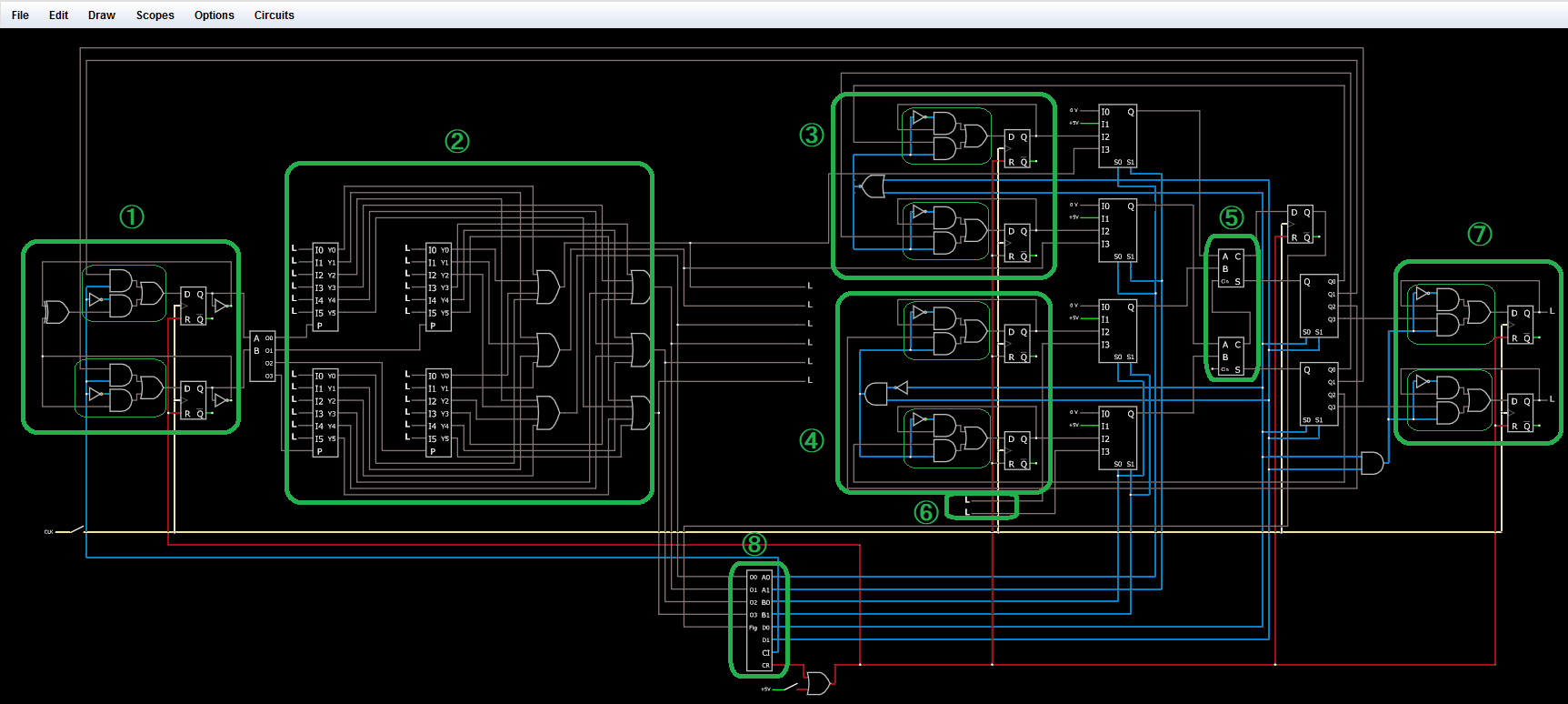
マルチコアCPUのように複数のCPUが一つのメモリを共有するCPUシステムにおいて、
重要な命令の一つに「アトミックな処理」を担う命令があります。
「アトミックな処理」とは、複数の命令を1つの処理として行い、その途中で他の処理が割り込むことなく、全てが一度に実行されるような振る舞いを指します。
例えば、MIPSなどでは、メモリアクセスの命令はアトミックな処理を除けば
ロードとストアの命令しかなく、特定の番地のメモリの値を+1したいときは、
以下のようなアセンブリコードになるでしょう。
# メモリアドレスが$t0に格納されていると仮定
lw $t1, 0($t0) # メモリアドレス$t0番地から値を$t1レジスタにロード
addi $t1, $t1, 1 # $t1レジスタの値を+1
sw $t1, 0($t0) # インクリメントした値をメモリアドレス$t0にストア※ 0($t0)の初期値は0と仮定しています。MIPSのアセンブラ表記として、0($t0)は $t0 レジスタの値がメモリのベースアドレスを示し、そこからオフセット 0 の位置にあるメモリの値という意味になります(例えば、3($t0)なら$t0番地から3ワード(12バイト)先($t0+3)のメモリの値になります)。
上記は単純に$t0番地のメモリの値をインクリメント(+1)するものですが、この命令を2つのコアに分散して(+1を)実行し、結果的にメモリの値を+2しようとした場合、以下のように処理される可能性があります。
コア0: lw $t1, 0($t0) # メモリアドレス$t0から値を$t1にロード (コア0の$t1レジスタの値は0)
コア0: addi $t1, $t1, 1 # $t1の値を+1 (コア0の$t1レジスタの値は1)
コア1: lw $t1, 0($t0) # メモリアドレス$t0から値を$t1にロード (コア1の$t1レジスタの値は0)
コア0: sw $t1, 0($t0) # インクリメントした値を$t0に再度ストア ($t0番地のメモリの値は1)
コア1: addi $t1, $t1, 1 # $t1の値を+1 (コア1の$t1レジスタの値は1)
コア1: sw $t1, 0($t0) # インクリメントした値を$t0に再度ストア ($t0番地のメモリの値は1)
※ コア0の$t1レジスタと、コア1の$t1レジスタは物理的に別であることに注意してください(もちろん$t0も物理的には別ですが、同じ値(メモリ番地)が入っていることを仮定しています)。
上記の例では、$t0番地のメモリの値の初期値が0で、インクリメントを2回行って2になることを期待しましたが、結果は1になってしまいます。これは、メモリの値を更新する際に、1命令では処理できず、どうしても複数の命令が必要になることに起因します。
つまりメモリの値の更新をアトミック(不可分)な処理として1つの命令のようにふるまわせることができれば、この問題は解決します。
例えばMIPSでは、load-link (LL) と store-conditional (SC) という2つの命令の組を利用して、アトミックなメモリ操作ができるようになっています。
LLでは、メモリ位置から値をレジスタに読み込むと同時に、その位置へのリンク(監視)を確立します。他のプロセッサがリンクアドレスに書き込むとリンクが無効になります。SCでは、指定されたメモリアドレスに値を書き込みますが、書き込みはLL命令によって確立されたリンクがまだ有効である場合にのみ成功します。書き込みが成功した場合、レジスタに1がセットされ、失敗した場合は0がセットされます。0だった場合、LLからやり直すようにコードを組みます。
これによりメモリのロードからストアまでの間に、同じアドレスのメモリに他のコアからアクセスがあった場合は再処理を繰り返すことにより、最終的にはロードからストアまでの処理をアトミックに行うことができます。もちろん、LL/SCを実装するためには、対象のメモリアドレスを保存するリンクレジスタなど、CPUにその機構(回路)を追加する必要があります。
具体的なアセンブラコードは以下のようになります。
.data
a: .word 0 # 共有変数 a
.text
.globl main
main:
# CP0(コアプロセッサ0: 各コアに個別に存在し、各コアのシステム制御とステータス管理を担当)レジスタからコアIDを取得
mfc0 $t0, $15 # $t0 に CP0レジスタ 15 (プロセッサID) をロード (あくまで例)
# プロセッサIDに基づいて異なる処理を実行
beq $t0, 0, increment # $t0 が0の場合、increment へジャンプ
beq $t0, 1, increment # $t0 が1の場合、increment へジャンプ
increment:
# アトミック操作を使用して共有変数 a をインクリメント
retry:
ll $t1, 0(a) # 共有変数 a をロードリンク
addi $t1, $t1, 1 # a をインクリメント
sc $t1, 0(a) # 共有変数 a にストアコンディショナル
beqz $t1, retry # 失敗したらリトライ
# 各プロセッサが一度インクリメントした後、無限ループ
end:
j end # 無限ループ
※実際にはmain:の中の3つの命令(mfc0と2つのbeq)は不要ですが、便宜的に入れています。
このコードでは、コア0とコア1のどちらも共有変数 a をアトミックにインクリメントしますが、処理の順番は保証されていない点に注意が必要です。例えば、コア0が先にインクリメントしてからコア1がインクリメントすることもあれば、その逆にコア1が先にインクリメントすることもあります。どちらの場合も最終的には正しい2の値となります。並列処理ができる所以です。もし、処理の順番が逆だと期待する結果が得られない場合(例えば、+1してから2倍したい場合など)は、並列処理でなく逐次処理を行う必要があるため、そもそも2つのコアで処理しても高速化は困難となります。